面對實務資料時,經常會發現有 missing data 的問題存在。在 SAS 的諸多 PROC 程序中,會把含有 missing data 的觀測值整筆刪除,但這都是假設 missing data 是服從 MCAR(Missing Completely At Random) 或 MAR(Missing At Random)這兩種機制底下。如果不是,則刪除 missing data 的動作將會造成模式估計上的一些問題。也因此,資料插補(data imputation)的研究從 70 年代以來就一直沒有中斷過。而在各種資料插補的方法中,尤其以 1987 年的 Rubin 所發表的 multiple imputation(多重插補法,簡稱 MI)最膾炙人口。雖然 MI 並非無懈可擊,但是在許多統套軟體將 MI 打包成讓人容易使用的語法後,使用者可以很容易的用幾個簡單語法完成資料插補的工作。Yang C. Yuan 在 SUGI 25 上發表了關於 PROC MI 和 PROC MIANALYZE 兩個跟多重插補有關的語法使用方法,是 SUGI 系列文獻裡面少有地針對 MI 所做的詳細介紹。
整個 MI 推論的精髓主要是圍繞在下面三點:
- Missing data 被重複插補 m 次以產生 m 個完整資料集
- m 個完整資料集使用正規程序進行分析
- m 個結果將被合併以進行其餘的統計推論
- Rubin, D.B. (1987), Multiple Imputation for Nonresponse in Surveys, New York: John Wiley & Sons, Inc.
- Little, R.J.A. and Rubin, D.B. (1987), Statistical Analysis with Missing Data, New York: John Wiley & Sons, Inc.
首先先概略的介紹一下 PROC MI 的語法:
PROC MI [options];
BY variables;
FREQ variable;
MULTINORMAL [options];
VAR variables;在 PROC MI 後面的 options 有下列幾種:
- NIMPU=number:設定插補結果的次數,預設值是五,表示最後 PROC MI 會給你五個不同的插補結果。視情況可略做修正,數字越大所費的時間也相對越長。
- OUT=SAS-data-set:插補的結果可利用這個 option 另存新檔。這個新檔會保留原始變數名稱,並且新增一個名為 _imputation_ 的變數,用來表示這是第幾個插補的結果。換句話說,如果之前 NIMPU 設定成 3 的話, _imputation_ 就會出現 1, 2, 3。
- SEED=number:亂數生成所需要的「種子」。設定種子並沒有什麼特別的規則,隨便放一個數字進去即可。
- MAXIMUM=numbers:可限定插補數據的最大值。
- MINIMUM=numbers:可限定插補數據的最小值。
- ROUND=numbers:可將插補的數據做四捨五入。如果設定成 ROUND=1,則結果會四捨五入成整數,如果設定成 ROUND=0.1,則四捨五入到小數點第一位。如果一次有好幾個變數要四捨五入,可以同時放好幾個數字到這個選項裡面,如 ROUND = 1 0.1 0.01。
MULTINORMAL 後面的 option 則有:
- METHOD=[REGRESSION | PROPENSITY | MCMC]:METHOD 選項可以指定用什麼方式來做資料插補,常用的方法有 REGRESSION(regression method)、PROPENSITY(propensity score method)、MCMC(MCMC method)。
- CHAIN=[SINGLE | MULTIPLE]:設定在進行 MCMC 時要一次放一條 chain 進去(SINGLE)還是多條 chain(MULTIPLE)進去。通常都是放多條效果比較好。預設值是 MULTIPLE。
- INITIAL=[EM | INPUT=SAS-data-set]。這是在指定 MCMC 中,第一個步驟用什麼方法來計算期望值和共變異矩陣。通常都是用 EM algorithm,不過這邊也允許自己輸入特定的期望值和共變異矩陣(INPUT=SAS-data-set)。
- NITER=number:插補過程都是一連串的遞迴,我們可以利用 NITER 去設定遞迴的最大值。預設值是 30。
data Fitness1;
input Oxygen RunTime RunPulse @@;
datalines;
44.609 11.37 178 45.313 10.07 185
54.297 8.65 156 59.571 . .
49.874 9.22 . 44.811 11.63 176
45.681 11.95 176 49.091 10.85 .
39.442 13.08 174 60.055 8.63 170
50.541 . . 37.388 14.03 186
44.754 11.12 176 47.273 . .
51.855 10.33 166 49.156 8.95 180
40.836 10.95 168 46.672 10.00 .
46.774 10.25 . 50.388 10.08 168
39.407 12.63 174 46.080 11.17 156
45.441 9.63 164 54.625 8.92 146
45.118 11.08 . 39.203 12.88 168
45.790 10.47 186 50.545 9.93 148
48.673 9.40 186 47.920 11.50 170
47.467 10.50 170
;針對資料裡面的 missing data,利用 PROC MI 得方式來進行插補。範例程式如下:
proc mi data=Fitness1 seed=37851 out=miout1;
multinormal method=regression;
var Oxygen RunTime RunPulse;
run;輸出的報表如下所示:
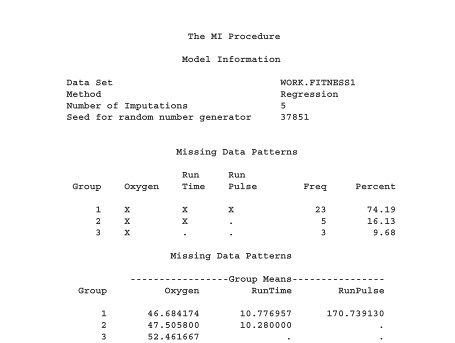
PROC MI 程序所提供的報表有兩個部分:
- Model information:此部分會提供一些資料和程序的基本訊息,包含資料集名稱、多重差補所使用的方法、差補的次數以及生成隨機亂數所需要的種子(seed)。
- Missing data pattern:此部分會顯示該資料集裡面的 missing data 是呈現何種 pattern。missing data pattern 大致上可以分類成 univariate nonresponse、multivariate two patterns、monotone、general、file matching 以及 factor analysis。有關這部分的介紹,詳見 Little & Rubin (1987) p.4~p.5。
以下便來介紹幾個在 MI 中常使用的差補方法:
- Propensity score method:簡單來說,propensity score method 就是利用 logistic regression model 來計算出每個觀測值會變成 missing data 的機率(此即 propensity score 的定義),然後用 propensity score 將觀測值分組,最後用 Bayesian bootstraping 來作資料插補。Propensity score method 的插補過程中,只有使用到該變數是否有 missing data 的訊息,而沒有特別去考量到該變數與其他變數之間的關係。
- MCMC method:MCMC 的全名是 Monte Carlo Marcov Chain。這是一個相當相當複雜的理論,其中光是 Monte Carlo 的部分就已經很複雜了,再牽涉到 Marcov Chain 的理論,便已經很難用三言兩語來解釋清楚。簡單來說,MCMC method 跟 EM algorithm 有點像,他也是分成兩個步驟來進行,分別是 I-step (Imputation step) 和 P-step (posterior step):
[I-step] 假設 Yi_mis 表示某變數 Yi 的 missing data、Yi_obs 表示某變數 Yi 有觀測到的資料,先估計變數的期望值以及共變異矩陣,算出 F(Yi_mis | Yi_obs) 這個條件機率,然後用這個條件機率去隨機抽出可插補 Yi_mis 的數據。
[P-step] 插補好後的「完整」變數,再去計算其事後的期望值和共變異矩陣,並求出新的 F(Yi_mis | Yi_obs),然後返回 I-step 去取代上一個條件機率。
重複上述步驟多次直到插補結果趨於穩定為止。
以下的程式範例是用來說明如何用 MCMC method 做多重插補。(用之前的資料)
proc mi data=Fitness nimpu=3 out=mioutmc;
multinormal method=mcmc;
var Oxygen RunTime RunPulse;
run;語法相當簡單,只要把第一個範例程式中的 method 從 regression 換成 mcmc 即可。nimpu = 3 表示產生三次不同的插補結果。out=mioutmc 表示將插補好的資料存成 mioutmc 這個新的資料集。
報表如下所示:
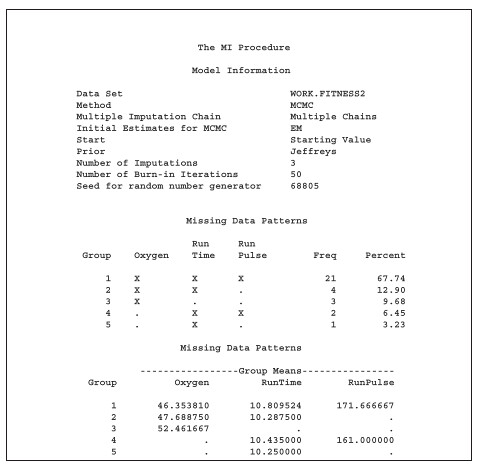
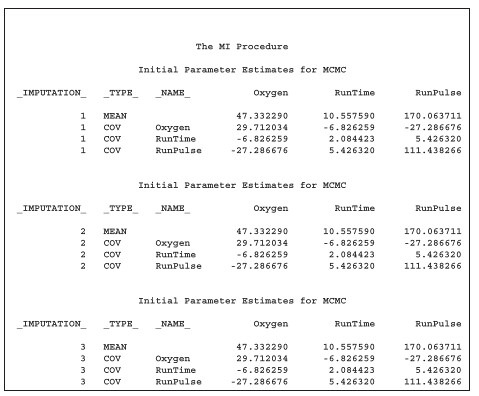
第一個報表和前面的報表一樣,用來表示一些資料訊息和 missing data pattern。第二個報表則列出一開始在做 I-step 時所用的期望值和共變異矩陣。三次插補的第一個 I-step 中所算出來的期望值和共變數矩陣一定是一樣的,因為這些結果是從最原始的數據所計算出來。第二個 I-step 後所產生的期望值和共變異矩陣就會開始不同了。因為每一次從 F(Yi_mis | Yi_obs) 所生成的數據都會不一樣,而利用這些生成的數據所算出的期望值和共變異矩陣當然也會跟著不一樣。
當 PROC MI 程序跑完後,會產生數個插補資料。此處並沒有什麼法則可以幫助選出「最好」的插補資料,而是用另一種方法讓所以插補資料綜合起來,來看整個插補過程是否達到預期。這個步驟可交由 PROC MIANALYZE 程序來完成。其基本語法如下:
PROC MIANALYZE [options];
BY variables;
VAR variables;在此特別介紹一些 PROC MIANALYZE 後面所需要用到的 option。
- ALPHA=p:為了要計算信賴區間所需的顯著水準,預設值是 0.05。
- EDF=numbers:用來指定 complete data 下參數估計所需的自由度。
- MU0=numbers:指定在 t-test 下的參數平均值的虛無假設 H0。如果只設定一個數字,則電腦會自動將這個數字分配給每一個變數。如果設定數個數字,則電腦會按照 VAR statement 後面所列的變數次序依序分配。
- MULT | MULTIVARIATE:要求電腦進行 multivariate inference。
- DATA=SAS-data-set:指定要分析的資料集。
- PARMS=SAS-data-set:設定分析時從 imputed data 中要用到的參數值。
- COVB=SAS-data-set:設定分析時從 imputed data 中要用到的共變異矩陣。
proc mi data=Fitness seed=37851 noprint out=miout;
var Oxygen RunTime RunPulse;
run;
proc reg data=miout outest=outreg1 covout noprint;
model Oxygen= RunTime RunPulse;
by _Imputation_;
run;
proc print data=outreg1(obs=8);
var _Imputation_ _Type_ _Name_ Intercept RunTime RunPulse;
title ’Parameter Estimates from Imputed Data Sets’;
run;這段主要是先用 PROC MI 做資料插補,五次插補的結果存成 miout 這個新的資料集。這個資料集會保留原來的 complete data,而 missing data 會被插補的數據取代。由於 PROC MI 沒有設定 NIMPU 這個選項,所以會產生預設值為 5 的五個插補結果出來。不同的插補結果會用新變數 _imputation_ 區別。
假設原始資料是要用來做線性迴歸,則可以照常跑 PROC REG,但記得要用 BY _imputation_ 替每個插補的結果配適不同的模型。配飾出來的結果另存於 outreg1 新檔中。
第三段 PROC PRINT 只是把 outreg1 印出來,沒有太特別的意義,可以忽略不跑。
接著,使用 PROC MIANALYZE 來分析結果:
proc mianalyze data=outreg1 mult edf=28;
var Intercept RunTime RunPulse;
run;產生報表如下所示。
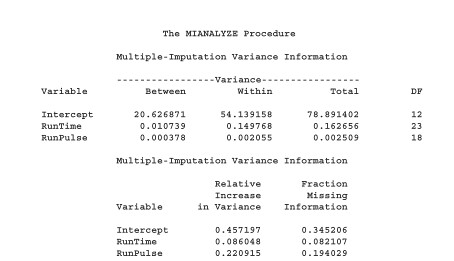
Multiple-Imputation Variance Information 這部分,提供了變數間的 between variance 和 within variance。這部分是拿來做計算條件分配 F(Yi_mis | Yi_obs) 的元素,不需要額外去作解釋。
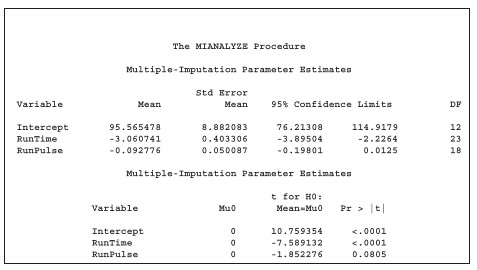
Multiple-Imputation Parameter Estimate 這部分,才是最需要進行解釋的部分。上半部只是各變數的敘述統計量,下半部則是利用 t-test 來檢定插補後的變數平均數是否等於插補前預定的變數平均數。如果插補的效果越好,則兩者會越接近,亦即表示經過 t-test 檢定後,p-value 應該要大於 0.05 以不拒絕虛無假設 H0:mean=mu0。
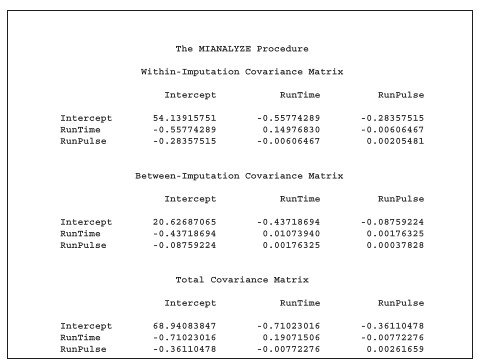
Multiple-Imputation Covariance Matrix 的報表是需要在程式內使用 MULT 這個 option 才會出現。主要是計算變數間的共變異矩陣。這個矩陣同樣也是拿來估算條件分配 F(Yi_mis | Yi_obs) 的元素。

最後一個表格是用來診斷多重插補法的工具。表格中的「Avg Relative Increase in Variance」是 missing data 所造成的變異數相對增量。理想中,這個值最好是零,這就表示完全沒有 missing data 存在,所以因為 missing data 所導致的變異數增量也相對不存在。因此在檢定時,我們也希望他能夠不顯著比較好。
CONTACT INFORMATION
Your comments and questions are valued and encouraged.
Contact the author at
Yang C. Yuan, SAS Institute Inc., 1700 Rockville Pike, Suite
600, Rockville, MD 20852. Phone (301) 881-8840 ext 3355.
FAX (301) 881-8477. E-mail Yang.Yuan@sas.com
本來看sas的help想學MI
回覆刪除看來看去都不懂
感謝你提供這篇簡單易懂的MI程式介紹
我在台大醫院統諮組當打雜的助理
請問若是proc mianalyze後發現插補效果沒有很好,但也只能使用的話,有許多次的imputation,最後要怎麼使用(就是我要怎麼把多個imputation後的資料變成後續要分析的資料)?
回覆刪除